Researchers at UC Berkeley Present EMMET: A New Machine Learning Framework that Unites Two Popular Model Editing Techniques – ROME and MEMIT Under the Same Objective



AI constantly evolves and needs efficient methods to integrate new knowledge into existing models. Rapid information generation means models can quickly become outdated, which has given birth to model editing. In this complex arena, the goal is to imbue AI models with the latest information without undermining their foundational structure or overall performance.
The challenge is twofold: on the one hand, precision is needed in integrating new facts to ensure the model’s relevance, and on the other, the process must be efficient to keep pace with the continuous influx of information. Historically, techniques such as ROME and MEMIT have offered solutions, each with distinct advantages. ROME, for instance, is adept at making accurate, singular modifications, while MEMIT extends these capabilities to batched updates, enhancing the model’s editing efficiency significantly.
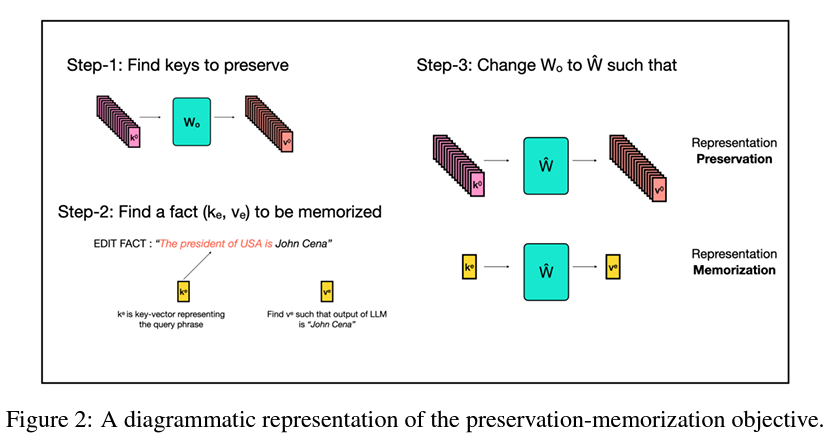
Enter EMMET, a groundbreaking algorithm devised by researchers from UC Berkeley, which synthesizes the strengths of both ROME and MEMIT within a cohesive framework. This innovative approach balances the meticulous preservation of a model’s existing characteristics with the seamless incorporation of new data. EMMET distinguishes itself by enabling batch edits, a feat achieved by carefully managing the trade-off between preserving the model’s original features and memorizing new facts. This dual focus is pivotal for upholding the model’s integrity while expanding its utility with current information.
The empirical evaluation of EMMET reveals its adeptness in managing batch edits effectively up to a batch size of 256, demonstrating a notable advancement in the field of model editing. This capability underscores the algorithm’s potential to enhance the adaptability of AI systems, allowing them to evolve alongside the growing body of knowledge. However, as the scale of edits increases, EMMET encounters challenges, highlighting the delicate equilibrium between theoretical objectives and their practical execution.
This exploration into EMMET and its predecessors, ROME and MEMIT, offers valuable insights into the ongoing development of model editing techniques. It emphasizes the critical role of innovation in ensuring that AI systems remain relevant and accurate, capable of adapting to the rapid changes characteristic of the digital era. The journey from singular edits to the batch editing capabilities of EMMET marks a significant milestone in the pursuit of more dynamic and adaptable AI models.
Furthermore, the performance metrics associated with EMMET, as revealed in empirical tests, showcase its efficacy and efficiency in model editing. For instance, on models like GPT2-XL and GPT-J, EMMET demonstrated exceptional editing performance, with efficacy scores reaching 100% in some cases. This performance is indicative of EMMET’s robustness and its potential to impact the landscape of AI model editing significantly.
The contributions of the UC Berkeley research team in developing EMMET are not just a technical achievement; they represent a pivotal step towards realizing the full potential of AI systems. By enabling these systems to stay current with the latest knowledge without sacrificing their core functionality, EMMET paves the way for more resilient and versatile AI applications. This evolution of model editing techniques from ROME and MEMIT to EMMET encapsulates the ongoing endeavor to harmonize the accuracy and efficiency of AI models with the dynamic nature of information in the digital age.
In conclusion, the advent of EMMET heralds a new era in model editing, where the balance between preserving existing model features and incorporating new information is achieved with unprecedented precision and efficiency. This breakthrough enriches the field of artificial intelligence and ensures that AI systems can continue to evolve, reflecting the latest developments and knowledge. The journey of innovation in model editing, epitomized by EMMET, underscores the relentless pursuit of adapting AI systems to meet the demands of a rapidly changing world.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
