This AI Paper from Microsoft and Tsinghua University Introduces Rho-1 Model to Boost Language Model Training Efficiency and Effectiveness



Artificial intelligence, particularly in language processing, has witnessed consistent advancements by scaling model parameters and dataset sizes. Noteworthy progress in language model training has traditionally relied on the extensive application of next-token prediction tasks across all training tokens. Despite the broad application of these techniques, the assumption that every token in a dataset contributes equally to the learning process is increasingly scrutinized. Significant inefficiencies are introduced when models are trained uniformly across all tokens, many of which may need to be more critical for the model’s performance and learning efficiency.
Existing research includes optimizing language model training through strategic data selection and curriculum learning. Traditional models like BERT utilize heuristic filters to enhance data quality, impacting model generalizability. Innovations such as Masked Language Modeling (MLM) focus on predicting a subset of tokens, increasing training efficiency. Studies also explore token-level dynamics, identifying ‘easy’ and ‘hard’ tokens influencing learning trajectories. This foundational work underpins advanced methodologies, paving the way for more focused training approaches that maximize the efficiency and efficacy of language models.
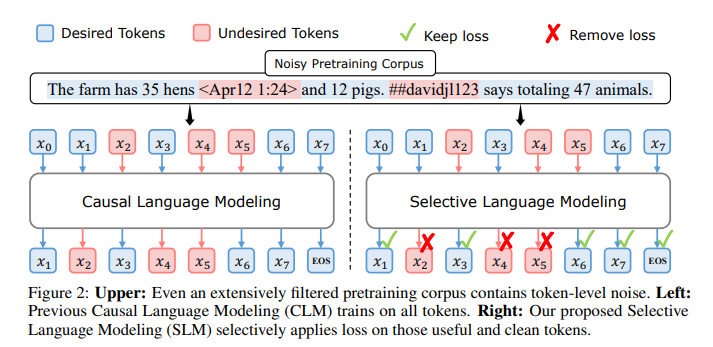
Researchers from Xiamen University, Tsinghua University, and Microsoft have introduced RHO-1, employing selective language modeling (SLM). This novel approach optimizes the training of language models by selectively focusing on tokens that significantly impact learning efficiency. Unlike traditional models that treat all tokens equally, RHO-1 identifies and prioritizes ‘high-utility’ tokens, enhancing training efficiency and model performance with less computational resource expenditure.
The RHO-1 methodology commences with training a reference model using a high-quality dataset to assess token utility. This model scores tokens, identifying those with the highest utility for focused training. Subsequent training phases only involve these selected high-utility tokens. This process was applied to the OpenWebMath corpus, consisting of 15 billion tokens, providing a comprehensive base for evaluating RHO-1’s efficiency. By concentrating on key tokens, RHO-1 maximizes computational resources and model learning efficacy, streamlining the training process and enhancing the model’s performance on targeted tasks.
Implementing Selective Language Modeling (SLM) within the RHO-1 models yielded substantial performance enhancements. Specifically, the RHO-1-1B model demonstrated an absolute increase in few-shot accuracy of up to 30% across nine mathematical tasks when trained on the OpenWebMath corpus. Further proving the effectiveness of SLM, after fine-tuning, the RHO-1-1B achieved a top score of 40.6% on the MATH dataset. Meanwhile, the larger RHO-1-7B model achieved an even higher accuracy of 51.8% on the same dataset. These models reached baseline performance up to ten times faster than those trained using traditional methods. This differentiation in performance between the RHO-1-1B and RHO-1-7B models clearly illustrates the scalability and effectiveness of SLM across different model sizes.
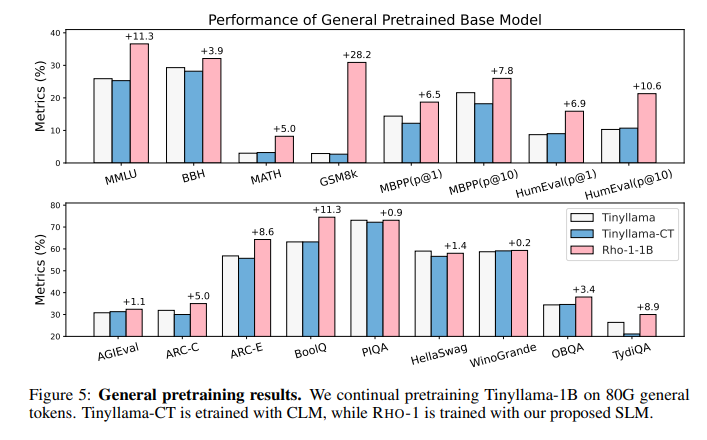
In conclusion, the research introduces the RHO-1 model, employing selective language modeling, developed through a collaboration between Xiamen University, Tsinghua University, and Microsoft. RHO-1 enhances efficiency by selectively focusing on high-utility tokens. By employing a reference model to score and select tokens for training, SLM demonstrated significant improvements in model efficiency and accuracy, as evidenced by performance gains on the OpenWebMath corpus. The results confirm that focusing training on the most impactful tokens can lead to faster learning and more precise model performance, making SLM a valuable advancement in artificial intelligence.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
